RAGアーキテクチャ三類型入門:Classic RAG / Graph RAG / Agentic RAGの違い¶
対象 / ポイント
対象: ChatGPTやLLMは使ったことがあるが、RAGの種類の違いをこれから整理したい人。
ポイント:
- Classic RAGは、近い文書を取ってくる方式。速く安い一方、関係性をたどる問いは苦手。
- Graph RAGは、文書間の関係をつなぐ方式。影響範囲の説明に向いている。
- Agentic RAGは、何を調べるかを考える方式。曖昧な問いで、計画、取得、検証、再計画を繰り返す。
「社内文書をChatGPTに読ませて、社員の質問に答えさせたい」という相談がある。 就業規則、申請マニュアル、製品仕様書、議事録がすでにあるなら、 AIがそれを読んで答えてくれるだけで便利だ。
ただし、素のLLMだけでは足りない。LLMは一般知識には強い一方、あなたの会社の最新ルール、非公開資料、部署ごとの例外までは知らない。知らない情報をもっともらしく補うこともある。
そこで使うのがRAGだ。 RAG(Retrieval-Augmented Generation)は、 回答前に外部知識を取り出し、その材料をLLMに渡して答えを作る仕組みである。 難しく言えば「検索で生成を補強する設計」だが、 まずは「必要な資料を引っ張ってきてから答える」と考えれば十分だ。
この記事の問いは1つだ。 Classic RAG、Graph RAG、Agentic RAGは、何がどう違うのか。 違いは動詞である。 Classic RAGは Retrieves(取ってくる)。 Graph RAGは Connects(つなぐ)。 Agentic RAGは Reasons(考える)。
3つの動詞で見るRAG¶
Retrieves
Classic RAGは、質問に近い文書を取ってくる。
Connects
Graph RAGは、人・製品・部署などの関係をつなぐ。
Reasons
Agentic RAGは、何を調べるべきかを考える。
比較の前に、共通点を固定する。3つのRAGはいずれも、社内文書やマニュアルなどをAIが使える形に整えるところから始まる。文書群を分けて文書ベクトルDBに保存する、という土台は共通だ。
違いが出るのは質問時だ。Classic RAGは、文書ベクトルDBから近い文書片を取ってくる。Graph RAGは、文書片に加えて関係グラフをたどる。Agentic RAGは、検索、グラフ、API、DBをツールとして選ぶ。
図は、上段が共通基盤、下段が差分だ。下段の右へ進むほど自由度は上がるが、レイテンシとコストも上がる。見るべきなのは、質問時の制御が Retrieves → Connects → Reasons と変わる点である。
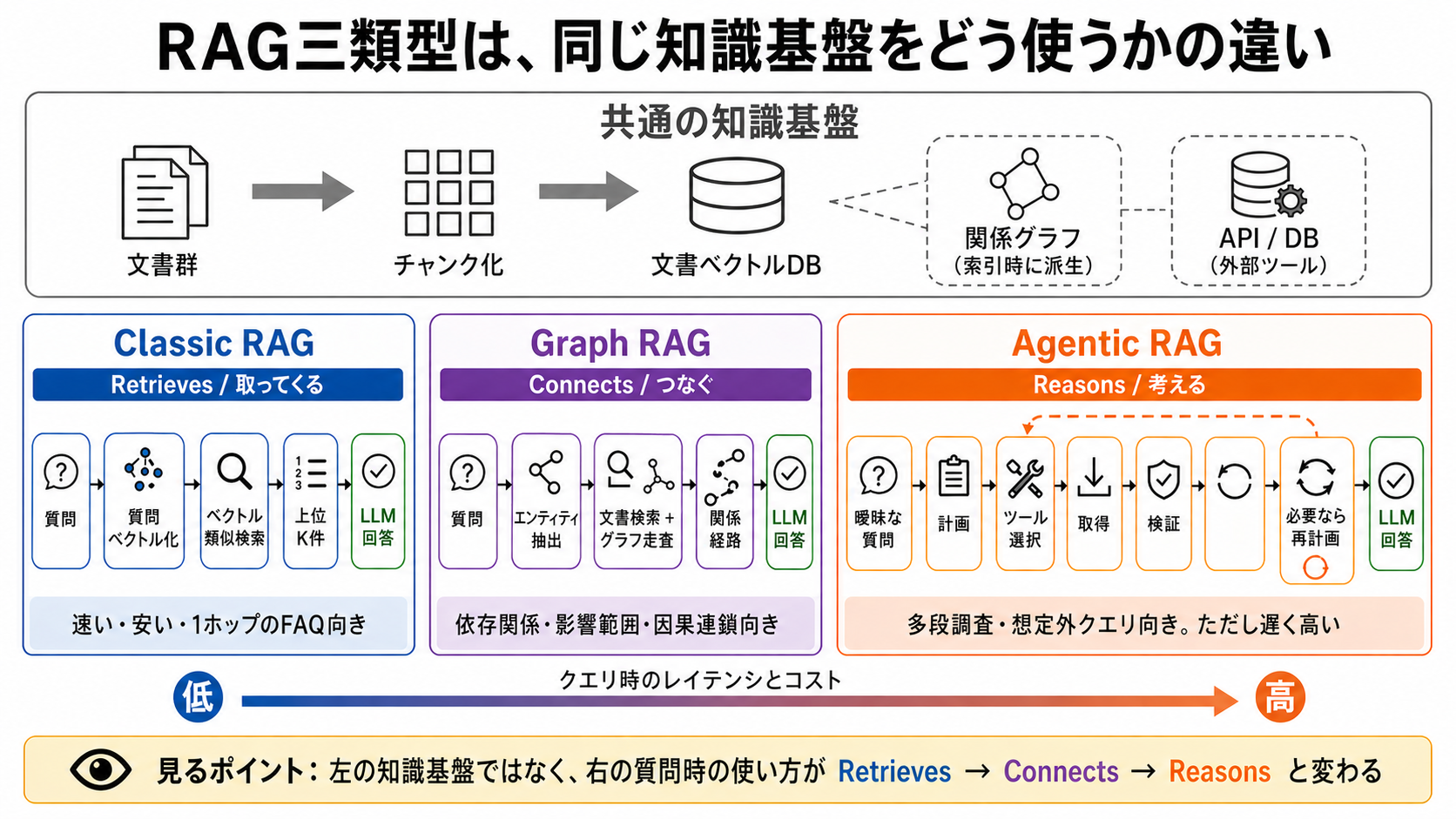
Classic RAG — Retrieves(取ってくる)¶
Classic RAGは、質問に近い文書を取ってきてから答える、もっとも素直なRAGだ。就業規則のFAQのように、答えがどこか1つの文書片に書かれている場合に向いている。
たとえば社員が「育児休業の申請期限はいつか」と聞いたとする。Classic RAGは、就業規則や人事マニュアルから意味が近い箇所を探し、その抜粋をLLMに渡す。LLMはその抜粋を根拠に回答する。
ここで出てくるベクトル検索は、文章の意味を数字の並びに変換して近いものを探す方法だ。文章を数字にする処理をエンベディングと呼ぶ。
正確には、まず文書群を小さな単位に分ける。各文書片をエンベディングして、ベクトルDBに保存する。質問が来たら、質問も同じ形式のベクトルに変換し、保存済みの文書ベクトルと近さを比べる。
つまり、質問だけをベクトル化するのではない。文書側は事前に、質問側は検索時にベクトル化する構成である。
Retrieves → 検索が1回で済む → 速く、安く、予測しやすい。
Classic RAGの流れは、事前処理と質問時処理に分けると整理しやすい。 事前には、文書群 → チャンク化 → 文書ベクトル保存、までを済ませる。 質問時には、質問 → 質問ベクトル化 → 類似文書K件 → LLMに渡す、という順に進む。 K件とは「上位何件まで使うか」という数だ。
強みは、速い、安い、実装しやすいことだ。多くのライブラリやベクトルデータベースが揃っており、FAQ、社内規程検索、製品マニュアル検索では最初の選択肢になる。
一方で、Classic RAGは「取ってくる」設計だ。質問に近い文書が取れなければ弱くなる。複数文書をまたいで関係をたどる問いでは、必要な断片が上位K件に入りきらないことがある。
詰まりどころは、関係質問だ。「Aさんの上司の上司は誰か」と聞かれたとき、所属表、上司一覧、組織改編メモが別々の文書にあると、類似検索だけでは答えに必要な経路を拾いにくくなる。
では、答えが文書の中ではなく、文書と文書の間にある場合はどうするか。 そこでGraph RAGが出てくる。
Graph RAG — Connects(つなぐ)¶
Graph RAGの土台はClassic RAGと同じだ。文書群を検索できる形にしたうえで、人、組織、製品、部品、取引先などの関係も保存して使う。答えが「この一文」ではなく、「AとBとCのつながり」にあるときに力を発揮する。
この「対象同士のつながり」を、ナレッジグラフと呼ぶ。ナレッジグラフは、知識を「製品Aは部品Bを使う」「部品BはサプライヤーCから調達する」のような関係として表したものだ。
Connects → 関係を先に作る → 影響範囲や因果連鎖を説明しやすくなる。
エンティティとは、文書に出てくる意味のある対象だ。製品名、部品名、会社名、人名、部署名などが該当する。Graph RAGでは、文書ベクトルに加えてエンティティと関係を取り出し、質問時に文書検索と関係走査を組み合わせる。
例として、「半導体不足の影響を受ける製品はどれか」と聞く場面を考える。 文書には「製品Xは制御基板Yを使う」「制御基板YにはチップZが必要」 「チップZはサプライヤーSから調達」と別々に書かれているかもしれない。 Graph RAGは製品 → 部品 → サプライヤーという経路をたどれる。
MicrosoftのGraphRAG資料でも、GraphRAGは生テキストから知識グラフを抽出し、 関係のまとまりを要約してRAGに使う構造として説明されている。 単純な意味検索だけでは拾いにくい「点と点をつなぐ」問いへの対応である。1
強みは、影響波及や因果連鎖の説明だ。「このサプライヤーが止まると、どの製品に影響するか」のような問いでは、文書片より関係図のほうが効く。
弱みもはっきりしている。グラフを作る初期コストが重く、エンティティや関係の抽出品質を保つ必要がある。変更が頻繁な領域ではメンテナンスも負荷になる。
さらに、グラフ化されていない領域には無力だ。点や線が作られていない情報はたどれない。関係を整備できる業務には強い一方、探索範囲が曖昧な問いには別の設計が必要になる。
では、そもそも何を調べるべきか最初に分からない場合はどうするか。そこでAgentic RAGが必要になる。
Agentic RAG — Reasons(考える)¶
Agentic RAGは、同じ文書検索基盤やグラフ、APIをツールとして持ち、検索する前に「何を調べるべきか」を考えるRAGだ。質問が曖昧で、手順が最初から決めきれない場合に向いている。
たとえば「うちの製品の売上が落ちた原因を分析して」と聞かれたら、最初に取るべき資料は1つではない。売上データ、価格改定履歴、広告出稿、競合ニュース、顧客問い合わせなど、複数の手がかりがある。
Agentic RAGでは、LLMが計画を立て、使うツールを選び、情報を取得する。 取得した根拠が十分か確認し、足りなければ再計画する。 ツールは、社内検索、データベース問い合わせ、Web APIなどだ。 LlamaIndexやLangChainの公式ドキュメントでも、エージェントは複雑な問いを分解し、 外部ツールを選びながら進める構成として説明されている。23
Reasons → 取得手順を都度決める → 適応力は高いが、遅く高くなりやすい。
ここでの差分は、データ基盤ではなく制御役だ。エージェントが、検索、関係確認、外部確認のどれを使うかを質問ごとに選ぶ。
強みは、想定外のクエリへの適応だ。質問に応じて調べ方を変えられ、自己検証で根拠不足に気づける可能性もある。
ただし、弱みは運用面に出る。LLM呼び出しが増えるため遅く、トークンコストも膨らむ。ツール選択や再計画が絡むため、デバッグも難しくなる。
Agentic RAGは万能ではない。単純なFAQに使うと、必要以上に考えすぎる構成になる。考える力が必要な問いにだけ使う、という線引きが重要だ。
選び方の指針¶
では、自分の業務ではどれを選ぶべきか。技術名から選ぶより、問いの形から逆算するほうが失敗しにくい。
Retrieves → Connects → Reasons の順に、自由度は上がり、レイテンシとコストも上がる。
まず、1回の検索で答えに届くか。 質問から答えの文書片にほぼ直接届く問いを、ここでは1ホップの問いと呼ぶ。 該当するなら、Classic RAGで十分なことが多い。
次に、答えに関係性が含まれるか。「この部品に依存する製品は」のように、点と点をたどるならGraph RAG寄りだ。
最後に、事前に手順を定義できるか。調査手順が質問ごとに変わるなら、Agentic RAGを検討する。
| RAG型 | レイテンシ | コスト | 得意領域 | 苦手領域 |
|---|---|---|---|---|
| Classic RAG | 低い。検索と生成が中心 | 低い | FAQ、マニュアル検索、規程確認 | 複数文書をまたぐ関係質問 |
| Graph RAG | 中程度。グラフ走査と要約が入る | 中〜高。構築と保守が重い | 影響分析、依存関係、因果連鎖 | グラフ未整備の領域、頻繁に変わる関係 |
| Agentic RAG | 高い。複数ターンになりやすい | 高い。LLM呼び出しが増える | 曖昧な調査、多段分析、想定外クエリ | 単純FAQ、厳密な実行時間が必要な処理 |
現実には、ハイブリッド構成が扱いやすい。 普段はClassic RAGで一次絞り込みをする。 関係が必要ならGraph RAGに進み、調査手順が読めないときだけAgentic RAGに進む。 LangChainのRAG資料でも、固定的な2-step RAG、エージェント型、 検証を挟むハイブリッド型が整理されている。4
すべてをAgenticにすると、コストも遅延も読みにくくなる。 よく使う質問は安く速く処理し、難しい質問だけ深く調べる。 これが実務では現実的だ。
まとめ:RAGは名前より動詞で覚える¶
RAGの亜種はこれからも増える。新しい名前が出るたびに覚え直すより、「その方式は何をしているのか」を動詞で見るほうが整理しやすい。
Classic RAGは、取ってくる方式だ。 Graph RAGは、つなぐ方式だ。 Agentic RAGは、考える方式だ。 この3つを押さえると、レイテンシ、コスト、適用領域の差も自然に見えてくる。
実装を考えるときも同じだ。 まずClassic RAGで足りるかを見る。 関係が答えならGraph RAG、調査手順そのものを決める必要があるならAgentic RAGだ。
新しいRAG手法を見たら、最初にこう問い直す。 何を取ってきているのか。 何をつないでいるのか。 何を考えているのか。 その動詞が分かれば、用途に合う設計を選びやすくなる。