A Beginner's Guide to Three RAG Architectures: Classic RAG, Graph RAG, and Agentic RAG¶
For / Key Points
For: Readers who have used ChatGPT or LLMs, but want a clear mental model for RAG variants.
Key Points:
- Classic RAG retrieves. It is fast and inexpensive, but weak at relationship-heavy questions.
- Graph RAG connects. It uses relationships across documents to explain impact paths.
- Agentic RAG reasons. It plans, retrieves, validates, and re-plans for ambiguous questions.
"Can we make ChatGPT answer questions from our internal documents?" This is often the first request teams make after trying LLMs. If policies, manuals, product specs, and meeting notes already exist, it feels natural to let AI read them and answer questions.
A plain LLM is not enough for that job. It may know general facts, but it does not know your latest internal policy, private product notes, or department-specific exceptions. When it lacks the answer, it can still produce a fluent but unsupported response.
That is where RAG comes in. RAG, or Retrieval-Augmented Generation, is a design pattern where the system retrieves external knowledge before asking the LLM to generate an answer. In simpler terms, it fetches the relevant material first, then answers with that material in view.
This article answers one question: how are Classic RAG, Graph RAG, and Agentic RAG different?
The shortest answer is verbs. Classic RAG retrieves. Graph RAG connects. Agentic RAG reasons. Those verbs explain why their latency, cost, and best-fit use cases differ.
RAG Through Three Verbs¶
Retrieves
Classic RAG retrieves text that is close to the question.
Connects
Graph RAG connects entities and relationships across documents.
Reasons
Agentic RAG reasons about what should be investigated next.
The three patterns do not start from three unrelated worlds. They all begin with the same raw material: documents, manuals, tickets, databases, or other knowledge sources that must be prepared for AI use.
The difference is how that prepared data is used at question time. Classic RAG retrieves nearby chunks from a vector index. Graph RAG uses those chunks plus a relationship graph. Agentic RAG treats search, graphs, APIs, and databases as tools it can choose from.
In the diagram below, the left side is the shared preparation layer: turning documents into usable knowledge assets. The comparison point is on the right, where each pattern controls retrieval differently at question time.
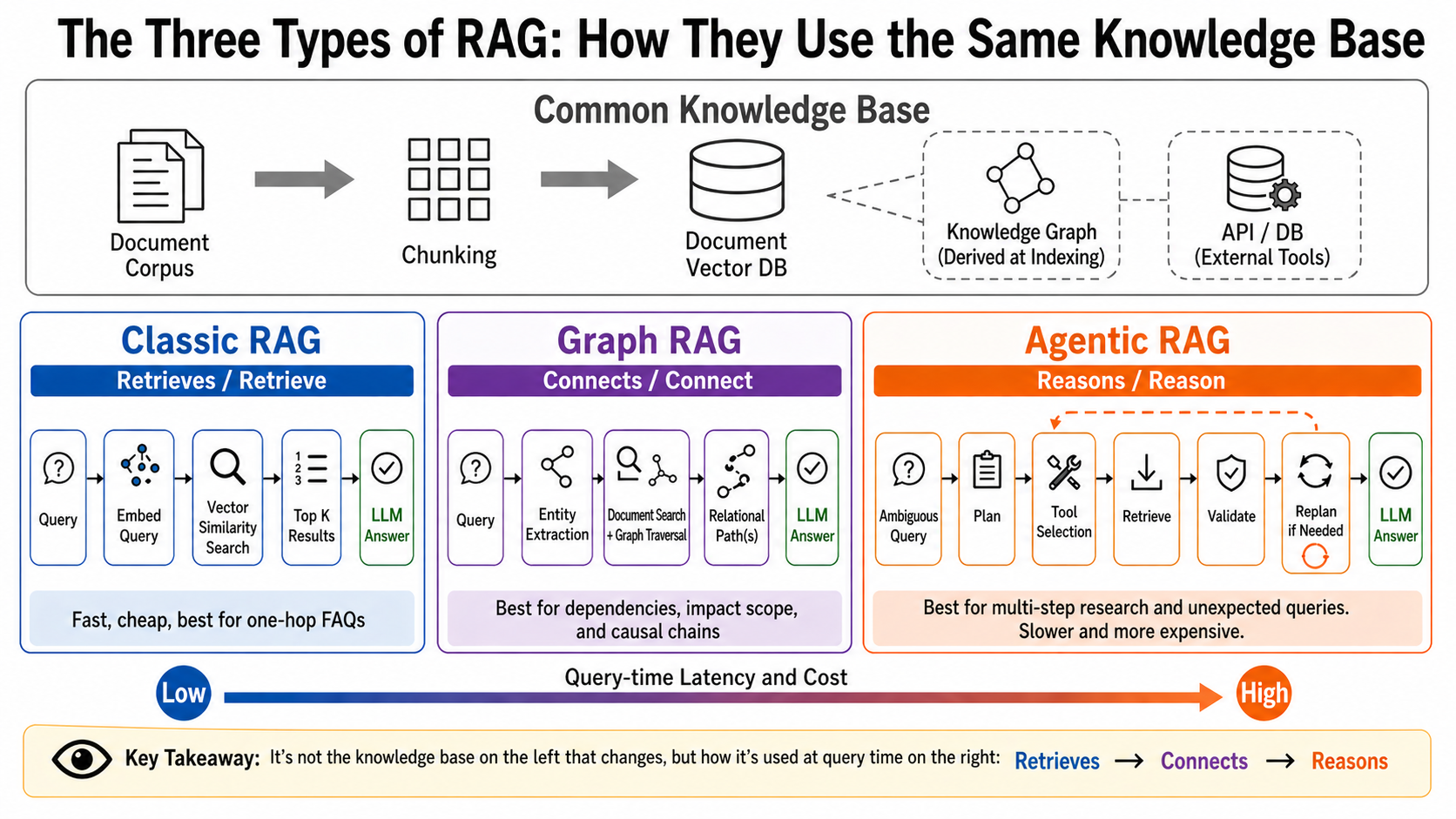
Classic RAG — Retrieves¶
Classic RAG is the most direct form of RAG: it retrieves text that looks relevant to the user's question, then gives that text to the LLM. It works well when the answer is likely to be present in one policy, one manual section, or one FAQ entry.
Imagine an employee asks, "When is the deadline for parental leave applications?" Classic RAG searches HR policy documents and employee manuals, retrieves the closest passages, and passes them to the LLM. The LLM then writes a natural answer grounded in those passages.
The common retrieval method is vector search. Vector search converts text into lists of numbers that represent meaning, then searches for nearby meanings rather than exact keyword matches. The conversion step is called embedding.
More precisely, the document corpus is split into chunks first. Each chunk is embedded and stored in a vector database ahead of time. When a question arrives, the question is also embedded into the same vector space, then compared with the stored document vectors. In other words, the system does not embed only the question; documents are embedded during indexing, and the question is embedded at search time.
Retrieves → one search step → fast, inexpensive, and predictable.
The flow is: documents → chunks → stored document vectors, then question → question embedding → top K similar chunks → LLM answer. "Top K" simply means how many matching chunks are passed forward.
The main strength is simplicity. Libraries, vector stores, and tutorials are widely available, and the pattern is easy to reason about. For FAQs, policy lookup, product manuals, and support knowledge bases, Classic RAG is usually the first architecture to try.
The limitation is built into the verb. Classic RAG retrieves. It does not naturally traverse relationships. When an answer requires multiple documents or a chain of relationships, the required evidence may not fit inside the top K results.
For example, "Who is A's manager's manager?" may require an employee directory, reporting-line document, and recent organization-change note. A similarity search may retrieve one of those documents, but miss the path across them. Classic RAG is good at fetching material; it is not good at walking relationships.
When the answer lives between documents rather than inside one document, Graph RAG becomes the better mental model.
Graph RAG — Connects¶
Graph RAG starts from the same document base, keeps the text searchable, and also extracts entities such as people, products, parts, teams, and suppliers as relationships. It is useful when the answer is not a single passage, but a path through connected facts.
This relationship structure is called a knowledge graph. A knowledge graph represents knowledge as statements such as "Product X uses Part Y" and "Part Y is supplied by Supplier Z." Instead of only reading text, the system can also follow the map of relationships.
Connects → relationships are prepared first → impact paths and causal chains become easier to explain.
An entity is a meaningful object in text: a product name, component, company, person, or department. Graph RAG stores document vectors and also extracts entities and relationships ahead of time, then combines text retrieval with graph traversal at question time.
Consider the question, "Which products are affected by a semiconductor shortage?" The relevant facts may be scattered: Product X uses board Y, board Y needs chip Z, and chip Z comes from supplier S. Classic RAG searches for similar passages; Graph RAG can follow the product → part → supplier path.
Microsoft's GraphRAG documentation describes the approach as extracting a knowledge graph from raw text, building a community hierarchy, generating summaries, and using those structures during RAG tasks. This directly addresses questions that require connecting dots across a corpus.1
The strength is relationship reasoning. Graph RAG is well suited to impact analysis, dependency analysis, and explanations of how one change propagates through a system.
The weakness is maintenance. Building a graph costs time and money, and entity or relationship extraction must remain accurate. If teams, products, or suppliers change frequently, the graph needs ongoing care.
Graph RAG also cannot traverse what has not been modeled. It connects existing nodes and edges; if a domain is not represented in the graph, the system has little to follow. For open-ended investigation, another pattern is needed.
That is where Agentic RAG enters.
Agentic RAG — Reasons¶
Agentic RAG has the same search base, and may also have a graph, APIs, or databases as tools. It first decides what should be investigated. It is useful when the question is ambiguous, multi-step, or impossible to answer with a fixed retrieval process.
Suppose someone asks, "Why did sales for our product decline?" There is no single obvious source to retrieve. The answer may require sales data, pricing history, campaign changes, competitor activity, support tickets, and inventory status.
Agentic RAG lets an LLM plan, choose tools, retrieve information, validate whether the evidence is sufficient, and re-plan if needed. A tool can be internal search, a database query, a web API, or a spreadsheet reader. LlamaIndex and LangChain documentation describe agents as systems that break down complex questions, choose tools, and retrieve information through decision loops.23
Reasons → retrieval steps are chosen dynamically → adaptability rises, but latency and cost rise too.
In Agentic RAG, the left-side data foundation is not fundamentally different from Classic or Graph RAG. The difference is on the right: the agent decides whether to use search, graph traversal, or an external lookup for the current question.
The main strength is adaptability. The system can change its retrieval strategy depending on the question. With validation steps, it can also notice that the current evidence is incomplete and look for more.
The operational weakness is significant. More LLM calls mean higher latency and higher token cost. Because tool selection and re-planning are involved, debugging the path to a final answer is harder.
Agentic RAG is not a default choice for every workload. For simple FAQs, it is often too much machinery. It should be reserved for questions that genuinely need planning and revision.
How to Choose¶
Choose by the shape of the question, not by the name of the architecture. The first thing to inspect is how directly the question can reach the answer.
Retrieves → Connects → Reasons: flexibility increases, and so do latency and cost.
First, can the query be answered in one hop? A one-hop query reaches a relevant passage almost directly. Questions like "What is the warranty period for Product A?" or "What is the vacation request deadline?" usually fit Classic RAG.
Second, does the answer contain relationships? If the question asks which products depend on a component or who sits in an approval chain, Graph RAG is a better fit. The relationship map matters more than the individual document snippets.
Third, can the procedure be defined in advance? If not, consider Agentic RAG. Questions like "Analyze why sales declined" or "Investigate the background of this support issue" require the system to decide what to check next.
| RAG type | Latency | Cost | Strong at | Weak at |
|---|---|---|---|---|
| Classic RAG | Low. Mostly retrieval plus generation | Low | FAQs, manuals, policy lookup | Relationship questions across documents |
| Graph RAG | Medium. Graph traversal and summaries add work | Medium to high. Graph construction and maintenance cost more | Impact analysis, dependencies, causal chains | Unmodeled areas and rapidly changing relationships |
| Agentic RAG | High. Often multi-turn | High. More LLM calls and tokens | Ambiguous research, multi-step analysis, unexpected queries | Simple FAQs and strict latency requirements |
In practice, hybrid systems are often the most realistic option. Start with Classic RAG for initial narrowing, then escalate to Graph RAG or Agentic RAG only when the answer is incomplete. LangChain's retrieval documentation similarly distinguishes fixed two-step RAG, agentic RAG, and hybrid RAG with validation steps.4
Using Agentic RAG for everything makes cost and latency hard to predict. Using only Classic RAG causes failures on relationship-heavy or multi-step questions. Use cheap and fast retrieval for common questions, then spend more reasoning only when the query deserves it.
Summary: Remember the Verb, Not Just the Name¶
New RAG variants will keep appearing. Instead of memorizing every label, ask what the architecture is doing.
Classic RAG retrieves. Graph RAG connects. Agentic RAG reasons. Once those verbs are clear, the trade-offs in latency, cost, and use case fit become easier to see.
When you encounter a new RAG method, ask three questions. What does it retrieve? What does it connect? What does it reason about? The verb will usually tell you whether the design fits your use case.