LLM Wiki Architecture: Karpathy's Markdown Knowledge Base Pattern Explained¶
For / Key Points
For: Developers and technical leads who use RAG or long-context workflows, but feel that useful knowledge disappears into chat history instead of becoming reusable context.
Key Points:
- LLM Wiki does not remove RAG. It compiles raw sources into a persistent wiki, then retrieves from both wiki pages and raw sources.
- The central ingest step turns sources into durable artifacts through analysis and generation.
- The hard parts remain: information loss, nondeterministic generation, schema design, and retrieval over the wiki itself.
If an LLM workflow searches similar chunks and regenerates the same summary every time, the knowledge is not yet an asset. The answer may be useful. But it does not compound.
Karpathy's llm-wiki.md proposes a different direction: let an LLM maintain a Markdown wiki outside the model's context window.1 nashsu/llm_wiki implements that idea as a desktop OSS application.2
This article reads the pattern through the diagram below.
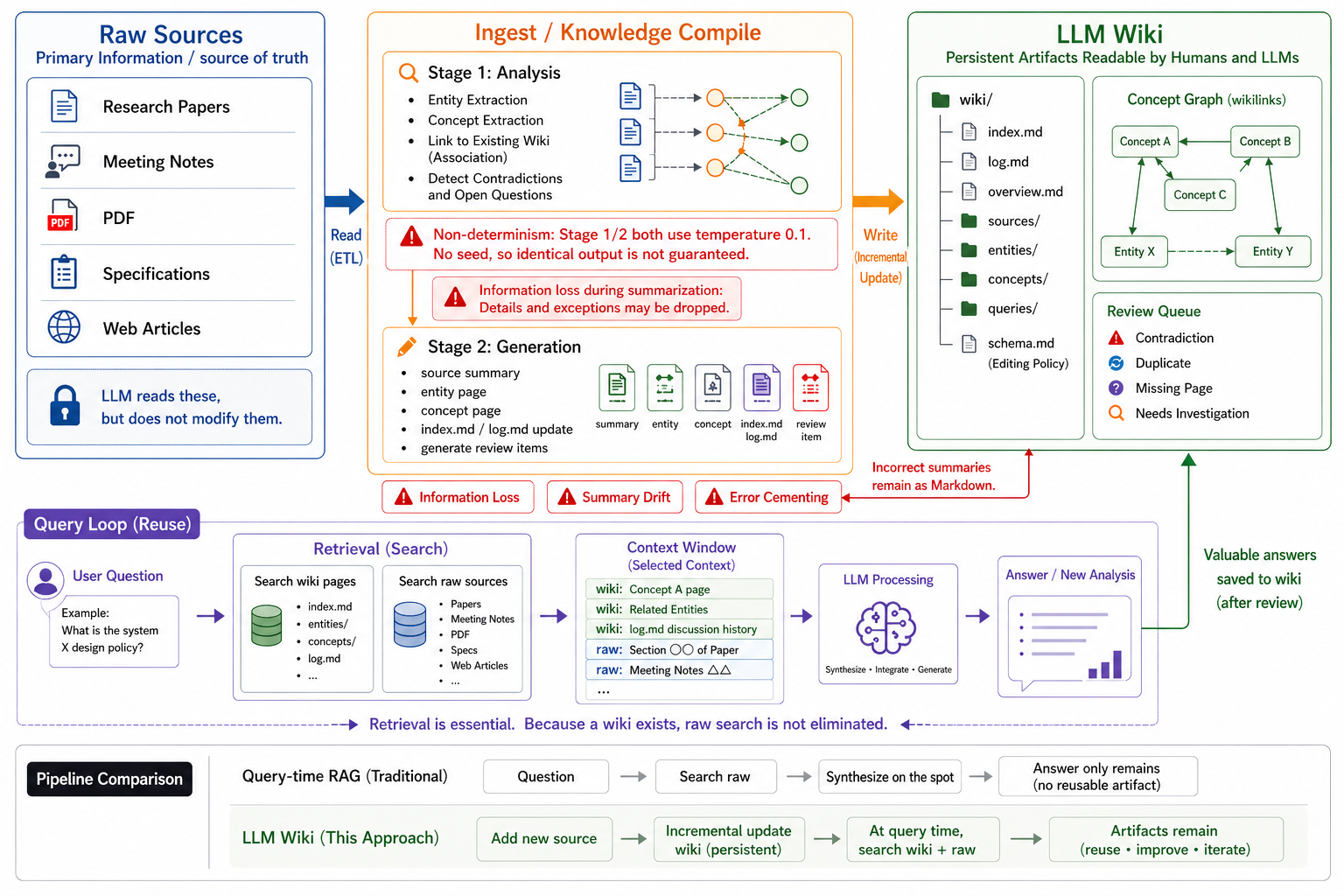
The most important part is the query loop at the bottom. LLM Wiki does not make retrieval disappear. It adds a persistent wiki layer, then retrieves from both wiki pages and raw sources.
This article answers one question: what does LLM Wiki solve, and what weakness remains?
The Diagram in One Pass¶
The top row shows what happens when a source is added. Raw Sources enter the ingest pipeline, the LLM analyzes and generates wiki artifacts, and the result is written into an LLM Wiki.
The bottom row shows what happens when a user asks a question. The system retrieves from wiki pages and raw sources, packs selected material into the context window, and the LLM produces an answer or analysis. If the answer is valuable, it can be saved back into the wiki.
Query-time RAG searches raw material at question time and synthesizes on the spot. LLM Wiki moves part of that synthesis earlier, when the source is ingested, and keeps the artifact.
| Lens | Query-time RAG | LLM Wiki |
|---|---|---|
| Main timing | When a question arrives | When a source is added and queried |
| What remains | Answer, logs, search results | Wiki pages, index, log, review items |
| Strength | Easy to start | Syntheses can be reused |
| Weakness | Re-synthesizes repeatedly | Information loss, nondeterminism, rules |
That distinction matters. LLM Wiki is not a superior replacement for RAG. It is a way to turn retrieved fragments into reusable external artifacts.
Left Side: Raw Sources Stay the Source of Truth¶
The left side of the diagram contains papers, meeting notes, PDFs, specs, and web articles. These are the primary materials the LLM reads. The LLM should not rewrite this layer.
That boundary is crucial. The wiki is useful, but it is not the raw source. If a wiki summary looks suspicious, the system must return to the original source.
For exact clauses, numbers, contracts, and experimental conditions, the wiki should not be the final evidence. It is a map. It is not the territory.
Center: Ingest Is Knowledge Compilation, Not Determinism¶
The center of the diagram is the core of LLM Wiki: Ingest / Knowledge Compile. In nashsu/llm_wiki, ingest is split into Stage 1 analysis and Stage 2 generation.3
Stage 1 reads the source and extracts entities, concepts, relationships to the existing wiki, contradictions, and open issues. Stage 2 uses that analysis to generate source summaries, entity pages, concept pages, index.md, log.md, and review items.
This split is sensible. It separates structure judgment from writing. That makes it easier to surface relationships and contradictions before the LLM emits files.
But this center step has three risks:
- Information loss: raw sources compressed into summaries lose details, caveats, and exceptions.
- Summary drift: the same concept page can change subtly as different sources are ingested.
- Frozen mistakes: a bad summary or vague link can become Markdown and then context for later questions.
Nondeterminism is also unavoidable. In nashsu/llm_wiki, both Stage 1 and Stage 2 streamChat calls pass { temperature: 0.1 }.3 Those calls do not pass a seed parameter.
So if the question is "will the same source produce the same wiki 100 times?", there is no guarantee. Within one project, unchanged files can be skipped through a SHA-256 ingest cache.4 That avoids regeneration; it does not prove regeneration would be identical.
LLM Wiki is not a deterministic knowledge compiler. It is a living draft maintained by an LLM.
Right Side: The Wiki Is Files, Graphs, and Review¶
The right side of the diagram shows what remains. The core is a Markdown file tree: index.md, log.md, overview.md, sources, entities, concepts, and queries.
On top of that, there is a concept graph and a review queue. The graph uses wikilinks to expose relationships. The review queue captures contradictions, duplicates, missing pages, and research tasks that need human judgment.
Without a Schema, this becomes an auto-summary pile. Schema is not just a prompt. It is the editorial policy of the wiki.
A minimal Schema would define verbs like these.
- ingest: read new raw files and split them into wiki/concepts/ and wiki/entities/
- query: start from wiki/index.md, then return to raw sources only when needed
- lint: detect broken wikilinks, orphan pages, missing sources, and stale claims
If the Schema is too loose, near-duplicate concept pages multiply. If it is too strict, ingest gets stuck on classification decisions. The more the LLM acts as editor, the more Schema determines quality.
nashsu/llm_wiki reduces some of this risk. For example, when an existing content page receives another source, it merges the sources field so provenance is not lost.5
But the body can still be replaced by the new LLM output. The same concept page can be subtly rewritten on each ingest from a different source. Provenance can survive while wording and emphasis drift.
Bottom Loop: Query Still Requires Retrieval¶
The bottom loop is the most important correction to the common misunderstanding. LLM Wiki does not remove retrieval.
When a question arrives, the system searches wiki pages. It also searches raw sources when needed. Then the selected wiki pages, raw passages, and log history are packed into the context window.
The LLM then reasons, integrates, and generates an answer. A useful answer can be saved back into the wiki. But that save should be treated as a reviewable update, not unquestioned truth.
This reveals the actual differentiation. If the goal is only answer accuracy or query cost, Graph RAG, re-ranking, long context, and agentic search remain alternatives. LLM Wiki is strongest when the synthesized output itself should become a durable artifact that humans and LLMs can revisit.
If nobody reads or reuses the artifact, classic RAG may be enough.
Where to Start¶
The decision is less about document count and more about reuse frequency. Even a small source set can justify a wiki if it is repeatedly read, compared, and updated.
The second decision is how much information can safely be compressed away. If you want a map of themes, relationships, and open questions, LLM Wiki fits. If exact details decide the answer, use the wiki as an entry point and return to raw sources.
| Situation | Start With |
|---|---|
| Mostly one-off FAQ lookup | Classic RAG |
| Repeated analysis over the same sources | Add an LLM Wiki layer |
| Relationships and contradictions matter | Wiki plus graph |
| Identical output is required | Do not rely on automatic wiki generation alone |
| Raw details decide the answer | Use the wiki as a map, then return to raw sources |
You do not need a full desktop app or knowledge graph on day one. Start with raw/, wiki/index.md, wiki/log.md, and explicit rules for ingest, query, and lint.
Summary: A Shelf Still Needs Maintenance¶
LLM Wiki does not ask whether RAG is outdated. It asks what remains after the model answers.
If only chat history remains, knowledge is buried. If only search results remain, the next session redoes the same synthesis. If wiki pages, indexes, logs, sources, and review items remain, the next LLM session starts from a better place.
But what remains is not automatically correct. LLM Wiki can turn knowledge into an asset, and it can also freeze a bad edit into future context.
The next focus in context design is not only window size. It is whether processed knowledge can become a verifiable external artifact. That is the value of LLM Wiki, and also its weak point.