The Loop Becomes the Unit of Work: Long-Running Task Design in OpenAI's Codex White Paper¶
For / Key Points
For: Engineers and team leads bringing AI agents into ongoing operational work rather than one-off tasks.
Key Points:
- The unit of work is moving from one prompt to a loop of context, memory, recurrence, and review
- Memory should live outside chat as a
vaultwhose changes can be reviewed through diffs - Long-running tasks need verifiable goals and explicit human decision points
OpenAI's Codex white paper is not only a feature tour for a coding tool. It points to a broader shift: work that used to fit into a single prompt is becoming a loop that carries context, returns to the task, and produces reviewable artifacts.1
The question is: when an AI agent works for a long time, what should we design as the real unit of work? The white paper uses creator Jason Liu's workflow to describe Codex as a place where work can live. This article focuses on the parts that matter most for practical engineering design: memory, recurrence, goals, and human decision points.
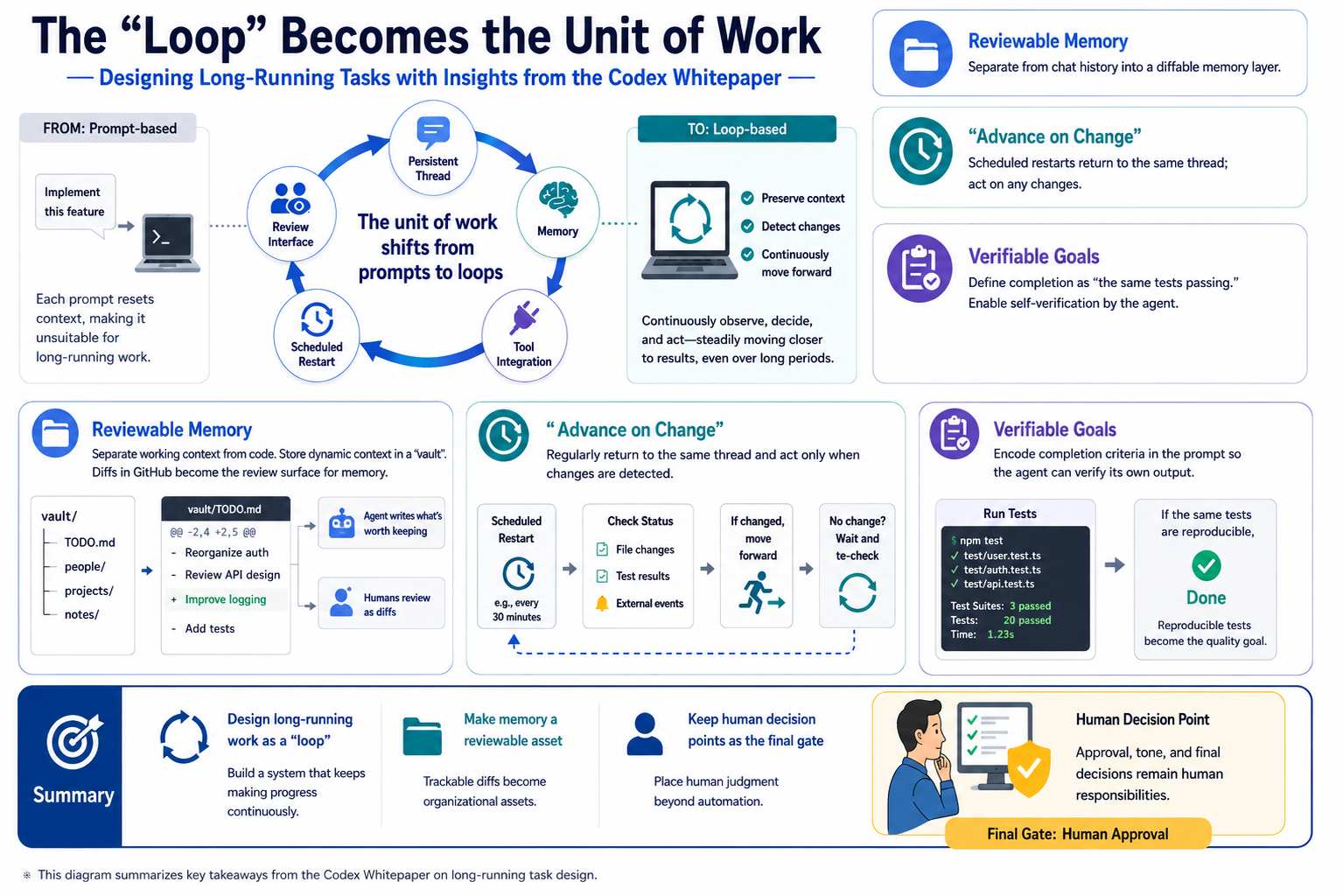
Figure: Design elements behind the shift from prompt-based work to loop-based work.
Work Moves From Prompt to Loop¶
For long-running tasks, the structure that returns to the same work matters more than the initial prompt. The white paper combines durable threads, a memory vault, tool connections, thread automations, and review surfaces into one operating pattern.1
Together, those parts give work state instead of letting it disappear inside a chat transcript.
- Durable threads hold context, preferences, decisions, and open questions
- A memory vault stores TODOs, people, projects, and agent notes outside the conversation
- Tool connections reach the places where work appears, such as Slack, Gmail, browsers, and GitHub
- Thread automations return to the same conversation on a cadence
- Review surfaces let the user inspect the artifact and turn comments into the next instruction
The center of gravity is not a smarter answer. It is the ability to preserve context, notice change, inspect an artifact, and return to the next action. That bundle is the loop.
Make Memory a Reviewable Asset¶
The longer a thread runs, the more it needs memory outside the conversation. The pattern in the white paper is a vault: a separate space for TODOs, people, projects, and notes.1
vault/
├── TODO.md
├── people/
├── projects/
├── agent/
└── notes/
The useful move is separation. The repository holds code. The vault holds the rolling context around the work. Preferences, decisions, reasons, and closed loops are hard to review when they exist only as impressions in conversation history.
When the vault lives in GitHub, diffs become the review surface for memory. The user can inspect what the agent considered important enough to write down. That is different from letting vague impressions accumulate in the chat. Only the changed memory needs review.
There is a tradeoff. Long-running threads carry context and can cost more to run than short fresh threads. Continuity can be worth it for important workstreams, but not every task deserves a long thread.
Change the Instruction to "Move It Forward When It Changes"¶
Thread automation changes the type of instruction. A normal prompt says: do this now. A recurring wake-up says: watch this, and move it forward when something changes.
For example, Codex might check Slack and Gmail every 30 minutes, find unanswered messages that need attention, research the context, and draft replies. It should still avoid sending anything without approval.
The point is that the thread does not rebuild context from zero each time. The white paper describes thread automations as recurring wake-up calls attached to the same conversation.1 Earlier decisions, notes, and open questions remain part of the loop, which makes it closer to work than to a plain cron job.
Verifiable Goals Define Done¶
The safety of a loop depends on whether the agent can check its own work against a real goal. The white paper contrasts weak goals with stronger goals that include expected behavior, review criteria, constraints, or a clear definition of done.1
A weak goal says: implement this plan. That leaves completion vague, so the agent has to infer what "done" means.
A stronger goal builds the success check into the task. For example: port a library while preserving the public API, use the original unit tests as the success check, and mark the work reviewable only after the same tests pass and differences are documented.
The Rich-to-Rust example makes the distinction clear. The target was not just to port the library. It was to port it in a way that could pass the original test suite. The tests became the real standard, and the work was not done until the new implementation passed them.
Keep Human Judgment Inside Every Loop¶
The loop examples in the white paper separate what the agent prepares from what the human decides. For chief-of-staff work, feedback monitoring, and refund handling, the agent prepares context, summaries, drafts, evidence, and next steps.
The human keeps approval, tone, timing, consent, and final decisions. Irreversible actions and external sends stay on the human side. Even if recurrence and remote control move the work away from the user's desk, the action boundary remains explicit.
So the white paper is not describing a fully autonomous agent. It gives work a place to live and a rhythm for returning to it, while preserving the decision points that should remain human. Long-running task design is moving from maximizing capability to designing boundaries.
Summary¶
The unit of work is shifting from a single prompt to a loop that combines context, memory, tools, recurrence, and review. Memory becomes safer when it is reviewable through diffs. Goals become safer when the agent can verify them against tests, constraints, or other concrete evidence.
The hard part of long-running task design is no longer just agent capability. It is defining done and creating the review surface. The next practical question is which parts of the work can be verified, and where human judgment must remain.